TensorFlowTM is an open source software library for high performance numerical computation using data flow graphs.
This document gives a quick introduction on how to get a first test program in TensorFlow running on Piz Daint.
Setup
To use TensorFlow on Piz Daint you have to load the corresponding module:
module load daint-gpu module load TensorFlow
or
module load daint-gpu module load TensorFlow/<module-version>
in order to specify a version. The command module avail TensorFlow can be used to have an overview of the available versions. For production runs, we recommend either to specify the version or to print it on the job's logs since different releases of TensorFlow might be incompatible. This can prove useful when revisiting old calculations.
Testing TensorFlow
Simple Import Test
On the Daint login node, directly try to import the TensorFlow module:
python3 -c 'import tensorflow as tf'
If you don't get an error, you should be able to use TensorFlow in your code.
Testing MNIST demo model
A more elaborate test is to actually train a model using the GPU. For that we can use the script mnist_convnet.py from the keras-io repository.
cd $SCRATCH salloc -N 1 -C gpu --account=<project> srun python3 mnist_convnet.py
Please replace the string <project> with the ID of the active project that will be charged for the allocation.
On the output you should find the lines that appear when TensorFlow finds the GPU:
pciBusID: 0000:02:00.0 name: Tesla P100-PCIE-16GB computeCapability: 6.0 coreClock: 1.3285GHz coreCount: 56 deviceMemorySize: 15.90GiB deviceMemoryBandwidth: 681.88GiB/s
At the end of the script, you should see something like
Test loss: 0.024193396791815758 Test accuracy: 0.9925000071525574
Running on Piz Daint
The following script exemplifies how to submit a TensorFlow job to the queuing system. The script asks for 1 node, making 12 CPUs available to the 1 Python task. Further, the job is constraint to the GPU nodes of Piz Daint and its running time is 10 minutes.
#!/bin/bash -l #SBATCH --job-name=test_tf #SBATCH --time=00:05:00 #SBATCH --nodes=1 #SBATCH --ntasks-per-node=1 #SBATCH --cpus-per-task=24 #SBATCH --constraint=gpu #SBATCH --account=<project> export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK module load daint-gpu module load TensorFlow/<module-version> srun python3 mnist_convnet.py
Running distributed TensorFlow with Horovod
Horovod is a distribution framework developed by Uber to make distributed Deep Learning fast and easy to use. It can be used to perform distributed training with TensorFlow and Keras. On Piz Daint, Horovod can by accessed by loading the module Horovod/<module-version>.
Horovod needs to be run with the same version of TensorFlow which it was compiled with. For this reason, a suffix was added to the name of the module to indicate the compatible version of TensorFlow. The template for the module's name is
Horovod/<horovod-version>-CrayGNU-X.X-tf-<tensorflow-version>
The command
module load Horovod/<module-version>
will load automatically the required version of TensorFlow.
Horovod was built on Piz Daint to use NCCL-2 to perform the synchronization of the model running on each node over the Cray Network. NCCL operations can be configured with a set of environment variables. Some of them are shown in the next section.
Example of a distributed job
As an example, let's train some convolutional neural network (CNN) models from the TensorFlow's benchmark repository on synthetic ImageNet data. The required scripts can be obtained with
git clone https://github.com/tensorflow/benchmarks.git cd benchmarks # checkout to a version available on Piz Daint: git checkout cnn_tf_v2.1_compatible
We will use the script benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py that calculates the total amount of synthetic images processed per second.
The following Slurm submission script can be used to run a distributed training job:
#!/bin/bash -l
#SBATCH --job-name=test_tf_hvd
#SBATCH --time=00:15:00
#SBATCH --nodes=<num-nodes>
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=24
#SBATCH --constraint=gpu
#SBATCH --account=<project>
module load daint-gpu
module load Horovod/<module-version>
export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK
# Environment variables needed by the NCCL backend
export NCCL_DEBUG=INFO
export NCCL_IB_HCA=ipogif0
export NCCL_IB_CUDA_SUPPORT=1
srun python <path-to-benchmarks-dir>/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py\
--model <model>\
--batch_size 64\
--variable_update horovod\
--train_dir ./checkpoints
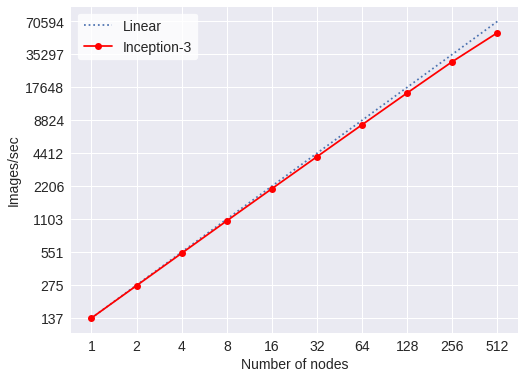
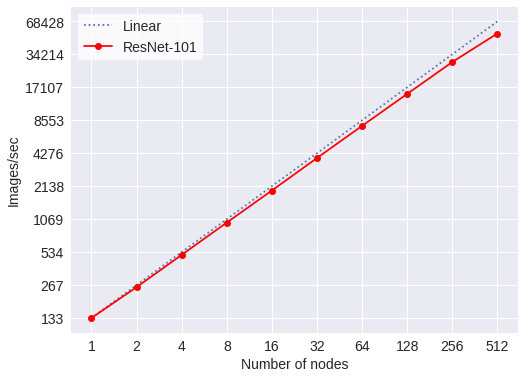
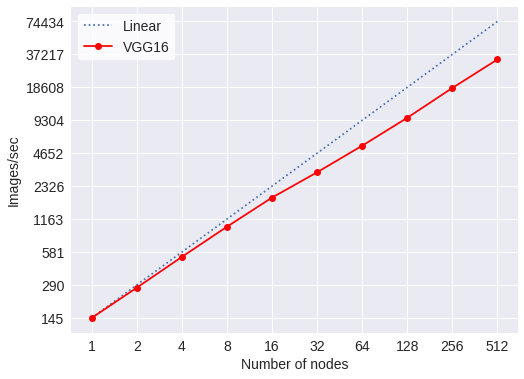
The following figures show the scaling of the throughput in images/second of some popular CNN models. For these models, <model>, on the batch script above should be replace by the vgg16, resnet101 and inception3.